The problem: a backlog of hundreds of millions of scanned PDFs with no practical way to extract the data inside them. The solution: two Amazon Bedrock inference pipelines that let you choose between speed and cost — and switch between them per document.
Introduction
Most enterprises have a document problem they have never fully solved. Invoices, contracts, lease agreements, medical records, compliance filings — years of business history locked inside scanned PDFs, image files, and paper archives. The information is there. Getting it out in a structured, usable form has historically required either armies of manual reviewers or brittle OCR software that stumbles the moment a document breaks from a standard format.
Generative AI changes that calculus. Large language models can read a scanned document, understand its structure regardless of how it was formatted, and return clean, structured data. The challenge shifts from "can the AI extract this?" to "how do we run this at scale, reliably, and affordably?"
On June 11, 2026, AWS engineers Tim Shear, Cecilia Li, and Said Benallal published a detailed walkthrough of an intelligent document processing (IDP) solution they built on Amazon Bedrock — one that directly addresses the scale and cost problem with two distinct inference pipelines that can be triggered dynamically depending on how quickly results are needed.
The Real-World Problem Behind This Solution
The architecture in this post was not designed in the abstract. It was built for a specific type of customer challenge: an organization sitting on hundreds of millions of scanned land lease documents stored as PDFs — the kind that contain only images with no selectable or searchable text — with new documents arriving daily.
Land lease documents present several layers of complexity beyond sheer volume. They are not standardized. Some present land tract information in numbered lists. Others use tables. Some include detailed land drawings. A single extraction approach designed for one format fails silently on another. Manually reviewing documents at hundreds-of-millions scale is not a realistic option. Standard OCR tools that rely on fixed templates break apart when document formatting varies.
The extracted sample data — from real Texas county land records (Winkler, Andrews, and Sutton Counties) — illustrates what the pipeline is designed to pull out: tract numbers, state and county identifiers, abstract numbers, survey names, section and range designations, and land quarter descriptions. Structured, queryable fields from unstructured scanned images.
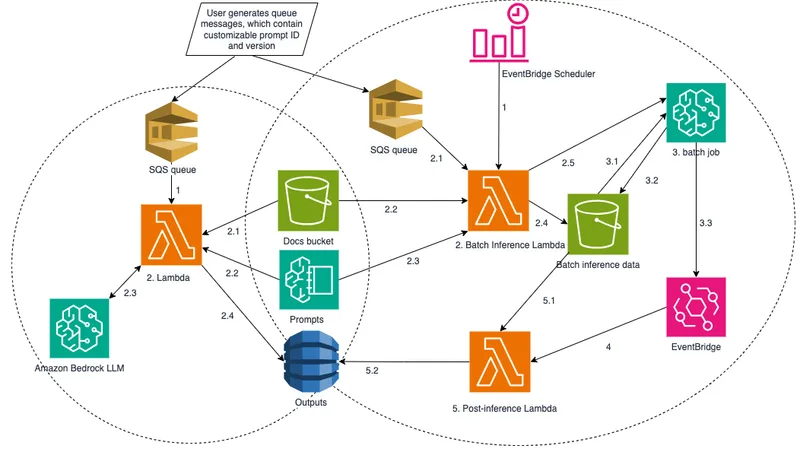
The Two-Pipeline Architecture: On-Demand vs Batch
The core design decision in this solution is the separation of document processing into two distinct pathways, both built on Amazon Bedrock, each optimized for a different priority.
On-Demand PipelineBatch Inference PipelineBest forTime-sensitive, single documentsHigh-volume, non-urgent backlogsProcessing styleOne document at a timeMultiple documents in one jobResponse timeReturns within secondsAsynchronous — no fixed timeRelative costStandard Bedrock pricing50% lower than on-demandQueue typeSQS FIFO (exactly-once delivery)SQS Standard (high throughput)Minimum documents1100ThroughputPer-message trigger1,000 docs in 15 minutesTrigger mechanismSQS message → LambdaEventBridge Scheduler → Lambda
Both pipelines share the same prompt management system, the same model flexibility, and the same output destination. What changes is when and how processing happens — and what it costs.
Pipeline One: On-Demand Processing
How a Document Enters the System
A message is sent to an AWS SQS FIFO queue containing everything the pipeline needs to process a single document: the document identifier, the S3 location of the file, the LLM model ID to use, and the prompt ID and version to retrieve from Bedrock Prompt Management.
The FIFO queue is a deliberate choice over a standard queue. It guarantees that each message is delivered exactly once — critical when each processing event triggers a paid AI inference call. It also preserves strict ordering within each message group, which matters when documents have dependencies or need to be processed in sequence. Each document producer can use a unique Message Group ID to maintain order for its own stream independently of others.
What the Lambda Function Does
When the queue message arrives, it triggers an AWS Lambda function that handles the full extraction workflow in sequence:
Step 1 — Fetch and convert. The Lambda downloads the PDF from its S3 location. If it is a scanned PDF — images only, no text layer — it converts every page into PNG images so the multimodal LLM can process them visually.
Step 2 — Handle large documents. This is where an important technical constraint comes in. Claude Sonnet 4, the model used in the demonstrated implementation, accepts a maximum of 20 images per multimodal API call. Any document with more than 20 pages must be split into 20-page chunks before being sent to Bedrock. Each chunk is tracked in DynamoDB with its own doc_id, chunk_id, and the total chunk_count for that document — ensuring the full document can be reassembled after all chunks are processed.
Step 3 — Retrieve the right prompt. The Lambda fetches the exact prompt specified in the SQS message from Amazon Bedrock Prompt Management. Each prompt has a unique ID and a version number. This matters because different document formats need different extraction instructions — the prompt tailored for a numbered-list lease document will not work as well on a table-structured one. By specifying the prompt per document in the queue message, the same pipeline can serve completely different document types without any code changes.
Step 4 — Call Bedrock and save results. The Lambda composes the full request — prompt text plus images — and sends it to Amazon Bedrock via the Converse API. The model returns the extracted data as a JSON string. That JSON is parsed and stored in a DynamoDB table alongside the model performance metrics for that call. The SQS message is then deleted to confirm successful processing.
Pipeline Two: Batch Inference
Why Batch Exists
The on-demand pipeline is fast, but speed costs more. For the bulk of a document backlog — thousands or millions of files where getting results within the next few hours is acceptable — running each document through real-time inference is unnecessarily expensive. The batch pipeline cuts Amazon Bedrock inference costs by 50% by grouping documents into a single asynchronous job that Bedrock processes on its own schedule.
Scheduled Triggering
Rather than responding to individual queue messages, the batch pipeline runs on a schedule set via Amazon EventBridge Scheduler. At the scheduled time, a Lambda function fires and begins checking the standard SQS queue for work.
The Batch Lambda Workflow
The batch Lambda function is more complex than its on-demand counterpart because it must prepare an entire job payload before anything is sent to Bedrock.
Document collection and deduplication. The function loops through all messages currently in the queue. Because a standard SQS queue (unlike FIFO) does not guarantee exactly-once delivery, the function actively deduplicates — any document that appears more than once in the queue is processed only once.
Model selection. Each SQS message specifies which LLM to use. A Bedrock batch inference job can only process documents using one model per job. If the queued messages specify multiple models, the Lambda uses a polling mechanism to identify the most frequently requested model and submits that batch — handling other model requests in subsequent runs.
JSONL file creation. Bedrock's batch inference API requires documents to be pre-formatted as JSONL files (one JSON object per line). The Lambda converts all queued documents into this format. This step is parallelized using Python's multiprocessing module, which is what enables the pipeline to prepare 1,000 documents in under 15 minutes. The JSONL files are uploaded to a dedicated S3 bucket, alongside a metadata.json file that records all message attributes — SQS message IDs, document IDs, prompt versions, and project metadata — for use during post-processing.
Job submission. The Lambda submits the Bedrock batch inference job, referencing the S3 location of the JSONL input files and specifying where Bedrock should write the output.
What Bedrock Does Asynchronously
Once the job is received, Bedrock queues it internally. When processing begins, it reads the JSONL artifacts, runs inference across all documents, and writes the output JSONL to the S3 output bucket. When the job finishes, Bedrock automatically sends a job status change event to Amazon EventBridge.
Post-Processing
An EventBridge rule listens for that completion event and triggers a separate post-processing Lambda function. This function fetches the output JSONL from S3, parses the extracted results for each document, and writes the structured land tract data into the same DynamoDB table used by the on-demand pipeline. The storage format and output schema are identical across both pipelines — downstream consumers of the data do not need to know which pipeline produced a given record.
The Prompt Management Layer: One Pipeline, Many Document Types
One of the most practically useful aspects of this architecture is how it handles document variety without requiring separate pipelines for each format.
Amazon Bedrock Prompt Management acts as a centralized, versioned store for extraction prompts. Each prompt has a unique ID and can have up to 10 saved versions. Up to 50 prompts can be stored per AWS region. When a document is queued for processing, the SQS message includes the specific prompt ID and version that should be used for that document type.
This means that a scanned lease presented as a numbered list, a table-formatted document, and a land drawing can all be processed through the same pipeline — each using a prompt specifically designed for its format — without any routing logic in the pipeline code itself. Adding support for a new document type means creating a new prompt in Bedrock Prompt Management and referencing it in the queue message. No infrastructure changes required.
What the Extracted Data Looks Like
The Winkler County land lease example in the post shows what clean output from this pipeline looks like. From a scanned PDF image, the model returns a structured JSON array with one object per land tract:
{
"tract": 1,
"state": "Texas",
"county": "Winkler",
"abstract": "A-1239",
"survey": "PSL Survey",
"section": "8",
"range_block": "B2",
"quarter": "N/2 of N/2"
}
Four tracts extracted from one document, each with seven clean fields — ready for database storage, search indexing, or downstream analytical workflows. No manual review. No template matching. No brittle regular expressions.
Deployment and Cleanup
Both pipelines are deployed via AWS CloudFormation stacks, making setup and teardown repeatable and consistent. One important note for teams evaluating this: when a CloudFormation stack is deleted, the S3 buckets and DynamoDB tables are retained by default. The deletion policy is set this way deliberately to prevent accidental data loss. Those resources must be manually deleted from their respective AWS console pages if cleanup is required.
Key Technical Constraints to Know Before Building This
Teams planning to implement this architecture should be aware of three hard limits that affect design decisions:
1. Claude Sonnet 4 image limit — 20 per call. Any document exceeding 20 pages must be chunked. The chunking logic, DynamoDB tracking, and eventual reassembly must be accounted for in implementation.
2. Bedrock batch inference minimum — 100 records. The batch pipeline will not submit a job unless at least 100 documents are queued. Organizations with lower document volumes per cycle should either use on-demand exclusively or batch queue documents across a longer window before submitting.
3. Bedrock Prompt Management limits — 50 prompts per region, 10 versions per prompt. Organizations with a large variety of document types, or those iterating heavily on prompt design, should plan their prompt library structure carefully within these constraints.
Scaling Beyond Lambda
The architecture as described handles 1,000 documents in 15 minutes using Lambda with Python multiprocessing. For most organizations, that throughput is more than sufficient.
For teams dealing with truly extreme volumes — tens of thousands of documents in a single processing window — the AWS engineers point toward a natural next step: replacing the Lambda execution environment with AWS Batch. This removes Lambda's execution time limits and resource constraints, allowing a single Amazon Bedrock batch inference job to scale significantly further without architectural redesign.
Who This Architecture Is For
This solution is best suited for:
Enterprises with large PDF backlogs — especially scanned documents where standard OCR fails due to format variation
Organizations needing flexible processing tiers — some documents urgent, most not — where cost optimization matters
Teams working with diverse document types — the per-document prompt specification solves the "one prompt doesn't fit all" problem without building separate pipelines
AWS-native teams — the architecture is tightly integrated across Bedrock, Lambda, SQS, S3, DynamoDB, and EventBridge, making it most practical for organizations already working within the AWS ecosystem
Final Takeaway
The architecture Tim Shear, Cecilia Li, and Said Benallal describe is not a proof of concept — it was built for a customer processing hundreds of millions of real documents. The two-pipeline design solves a genuine tension that every large-scale document processing system faces: the need for speed on urgent requests and the need for cost efficiency on bulk workloads. By letting the caller specify the pipeline, the model, and the prompt at the individual document level, the same infrastructure serves both — and can adapt to new document types without being rebuilt.
For any organization sitting on a backlog of unstructured documents and wondering how to make that data useful, this architecture is a concrete, deployable starting point.

